Our Fed model runs on 36 numbers. Not one of them is politics
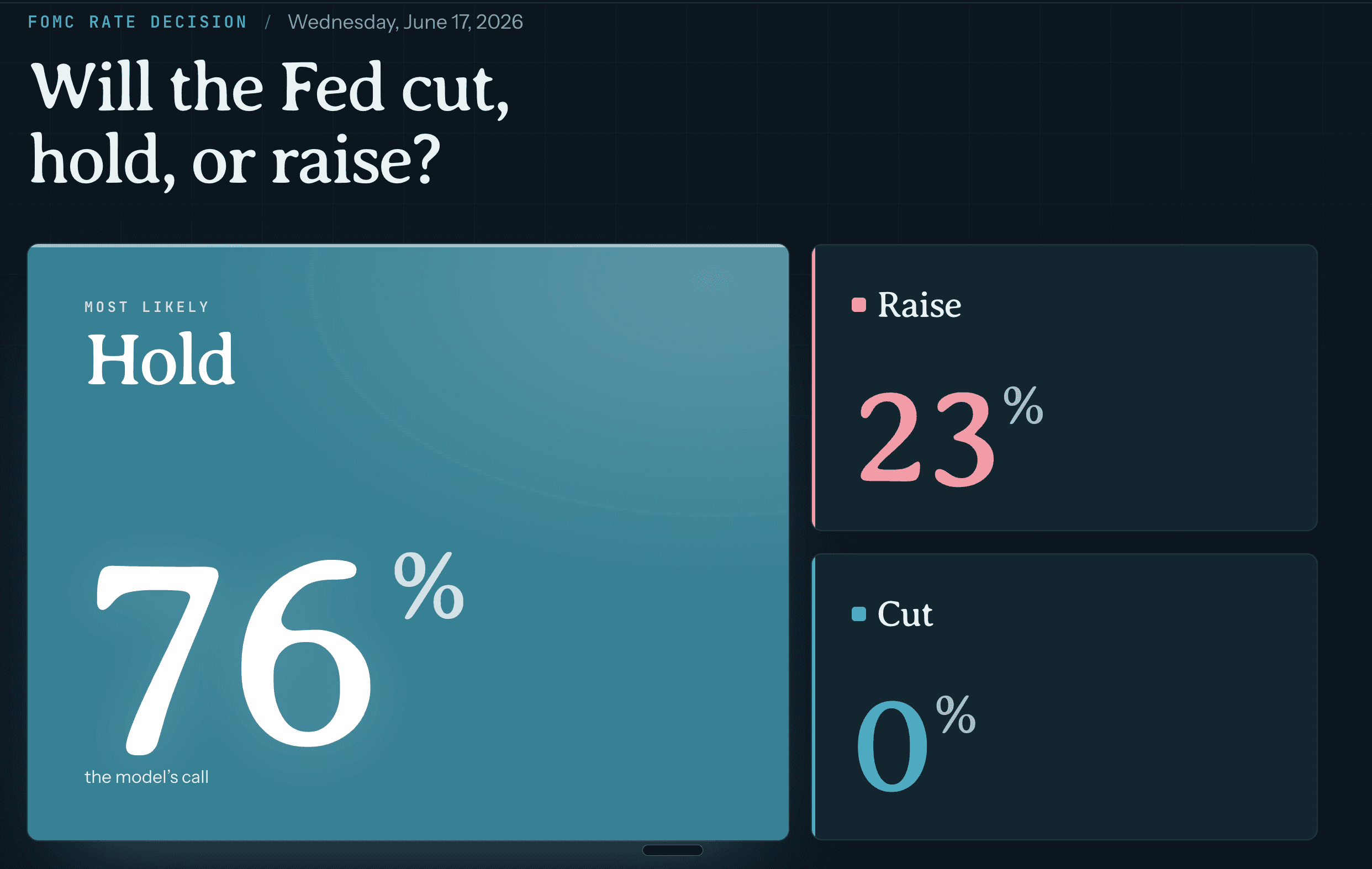
The Fed meets Tuesday and Wednesday, and on Wednesday afternoon it announces what it's doing with rates. Cut, hold, or hike.
Kalshi and Polymarket both put a hold at 99%, a hike under 1%, and a cut at basically zero.
Our model has it at 73% hold, 26% hike, 1% cut.
We're not predicting a hike. Hold is our most likely outcome too. But that 26% on a hike, against the market's sub-1%, is a wide gap, and it comes down to one thing: what's in the model and what isn't.
What the model sees
The model reads 36 inputs before each meeting, and every one of them is a number.
It sees the current Fed funds target and the recent path of rates, the last few decisions, the size of the last move, how long it's been since the Fed moved at all. It sees inflation five different ways, core and headline PCE, core and headline CPI, and how far core inflation is sitting above the 2% target. The labor market comes in through unemployment and nonfarm payrolls, both the latest month and the three-month trend. It has real GDP growth. And it reads the entire Treasury curve, the 3-month, 1-year, 2-year and 10-year yields, the spreads between them, and how the short end is pricing relative to the Fed funds rate.
That's the model. Thirty-six numbers, plus the Fed's history of what it did when those numbers looked a certain way.
Now look at what is not in there. There is no input for the war in Iran. None for who the Fed Chair is, what the President wants, or how a hike would land in the West Wing. The model has never heard of Kevin Warsh. It can read what the bond market expects, through the short end of the curve, but it cannot see a single piece of the politics.
So it does the only thing it can. It reads today's numbers, inflation running near 4%, a May jobs print of 172,000 against expectations near 85,000, and compares them to every setup the Fed has faced before. On that history, numbers like these are the kind the Fed has tightened into. The bond market is leaning toward a hold, but the inflation and jobs data are loud enough to keep a hike on the table anyway. So the model lands at 26%. It doesn't even know there's a war. It just sees the inflation that war is feeding into the headline numbers, and it reacts to the inflation.
Why prediction markets are at 99%
Because the market can price the one thing the model can't: the politics. This is Warsh's first meeting as Chair. Trump put him there to cut rates. The Fed is not going to open his term by hiking into the face of the White House, and the data doesn't support a cut either, so the only move that survives is a hold. Kalshi and Polymarket know all of that, so they collapse to 99%. Our model is pricing the data and the Fed's track record. The gap between 73% and 99% is, almost exactly, the politics our model can't see.
And it isn't crazy to lean hawkish here. The broader rates market already expects a hike. Fed funds futures are pricing roughly a 60% chance that rates are higher by year-end. The disagreement isn't hike or no hike. It's when. The rest of the market thinks it comes later. Our model thinks the data is already there.
Why not just raise rates?
Strip the politics out and look at the numbers the model is looking at. Inflation near 4%, twice the target. A labor market adding jobs at more than double what was expected. An oil shock from the war in Iran pushing the headline numbers higher. On that data, the case isn't for a cut. It's for a hike, or at the very least for not moving. The only reason a cut is even in the conversation is that the President wants one and the data doesn't.
This isn't really about Wednesday. The Fed holds Wednesday, everyone knows that. It's about the fact that a central bank staring at 4% inflation and an oil shock is being pushed to cut, and what that costs later when the politics wins and the data loses. Our model can't see the politics. That's the whole reason it gives you a clean read of what the numbers are actually saying.
The live model is at fedratewatch.impulselabs.ai. It's the same workflow any Impulse customer uses: upload the data, write a prompt, the agent builds the model. You can try it on your own data at impulselabs.ai.